Summary
View original tweet →Tinh Chỉnh Mô Hình Ngôn Ngữ Lớn: Kỹ Thuật và Góc Nhìn
Trong thế giới AI đang phát triển như vũ bão, việc tinh chỉnh các mô hình ngôn ngữ lớn (LLMs) đã trở thành một bước cực kỳ quan trọng để nâng cao hiệu suất của mô hình trong các ứng dụng cụ thể. Mới đây, một thread trên Twitter của anh bạn @_avichawla đã chia sẻ 5 kỹ thuật tinh chỉnh LLMs nổi bật, kèm theo giải thích siêu dễ hiểu và hình ảnh minh họa xịn sò. Bài viết này sẽ mở rộng thêm những insight từ thread đó, đi sâu vào các chi tiết và ý nghĩa của từng kỹ thuật, cũng như tương lai của machine learning.
Tinh chỉnh là gì mà hot thế?
Thread mở đầu bằng việc giới thiệu khái niệm tinh chỉnh (fine-tuning), nhấn mạnh tầm quan trọng của nó trong việc "độ" lại các mô hình đã được huấn luyện sẵn để phù hợp với các nhiệm vụ cụ thể. Tinh chỉnh giúp anh em tận dụng kho kiến thức khổng lồ của LLMs, đồng thời "độ" chúng để đáp ứng các yêu cầu riêng, như tuân thủ quy định dữ liệu hay chuyên môn hóa trong một lĩnh vực nào đó. Tweet đầu tiên như kiểu "mở bát" cho một hành trình khám phá 5 kỹ thuật tinh chỉnh, mỗi cái đều có hình minh họa siêu xịn
1. LoRA (Low-Rank Adaptation) - Tinh chỉnh kiểu "nhẹ nhàng"
Kỹ thuật đầu tiên được nhắc đến là LoRA, một giải pháp cho vấn đề "to bự" của LLMs. Tinh chỉnh kiểu truyền thống thì tốn kém lắm, nhất là với mấy mô hình hàng tỷ tham số. LoRA giải quyết bài toán này bằng cách thêm hai ma trận hạng thấp (low-rank) có thể huấn luyện, gọi là A và B, trong khi giữ nguyên phần lớn trọng số của mô hình. Cách này không chỉ giảm tải bộ nhớ và tính toán mà còn giúp anh em "chơi" được trên phần cứng khiêm tốn như Google Colab 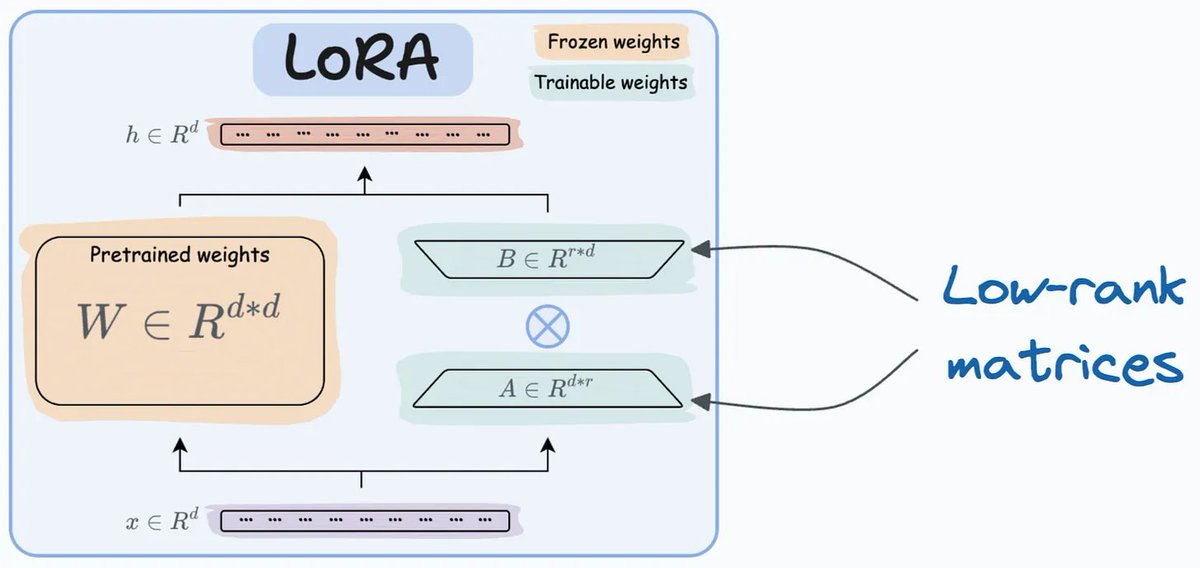 Hình minh họa đi kèm thì khỏi chê, nhìn phát hiểu luôn cách LoRA hoạt động
Hình minh họa đi kèm thì khỏi chê, nhìn phát hiểu luôn cách LoRA hoạt động
2. LoRA-FA - Phiên bản "tối giản" hơn
Tiếp theo là LoRA-FA, một biến thể tối ưu hơn bằng cách "đóng băng" ma trận A và chỉ cập nhật ma trận B. Kỹ thuật này giảm đáng kể số lượng tham số cần huấn luyện, đồng thời xử lý luôn vấn đề bộ nhớ kích hoạt (activation memory) mà LoRA gặp phải 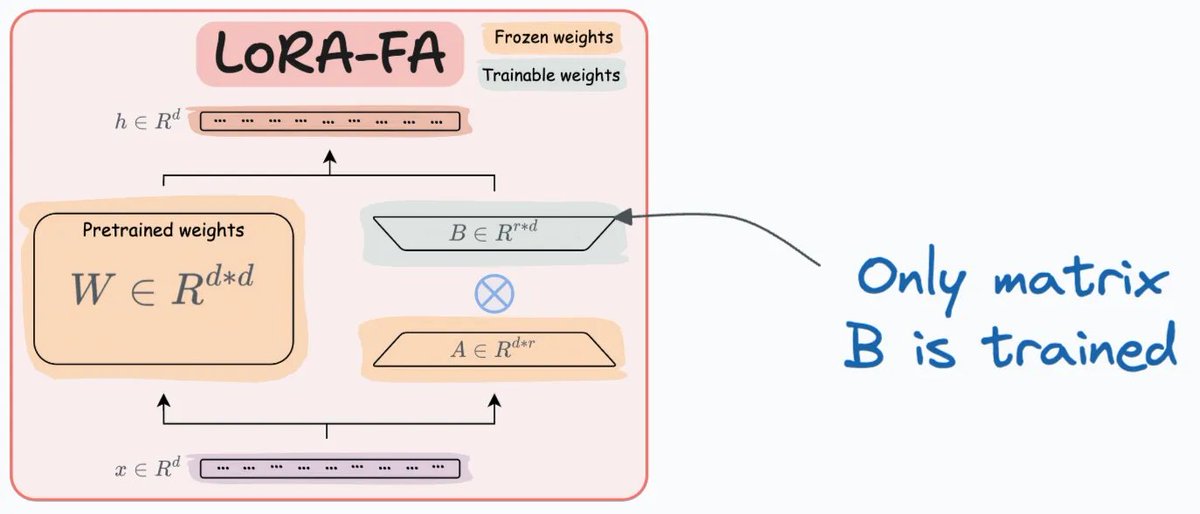 Hình minh họa đi kèm thì siêu rõ ràng, giúp phân biệt hai ma trận A và B dễ như ăn kẹo
Hình minh họa đi kèm thì siêu rõ ràng, giúp phân biệt hai ma trận A và B dễ như ăn kẹo
3. VeRA - "Chơi lớn" với ma trận ngẫu nhiên
Kỹ thuật thứ ba, VeRA, đi theo một hướng khác bằng cách sử dụng các ma trận A và B ngẫu nhiên, cố định và chia sẻ cho tất cả các tầng. Thay vì mỗi tầng có một ma trận riêng, VeRA học các vector tỷ lệ (scaling vectors) riêng cho từng tầng, giúp tăng hiệu quả và giảm độ phức tạp của mô hình 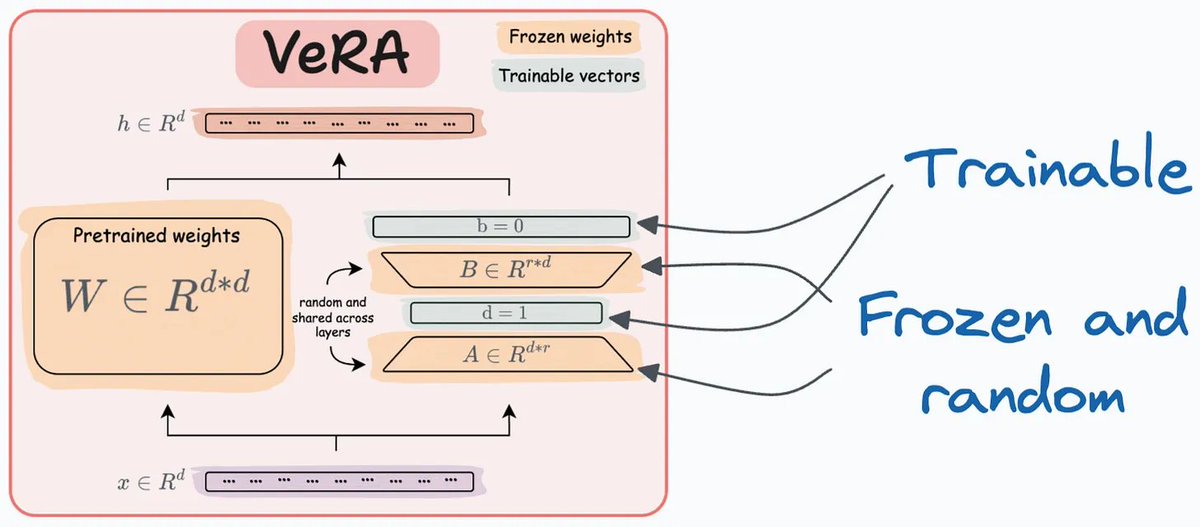 Hình minh họa thì đúng kiểu "nhìn phát hiểu ngay"
Hình minh họa thì đúng kiểu "nhìn phát hiểu ngay"
4. Delta-LoRA - Tinh chỉnh kiểu "năng động"
Kỹ thuật thứ tư, Delta-LoRA, giới thiệu một cách mới để cập nhật ma trận trọng số W. Thay vì tinh chỉnh kiểu truyền thống, Delta-LoRA thêm sự khác biệt giữa tích của ma trận A và B từ hai bước huấn luyện liên tiếp vào W. Cách này cho phép điều chỉnh linh hoạt hơn trong quá trình huấn luyện 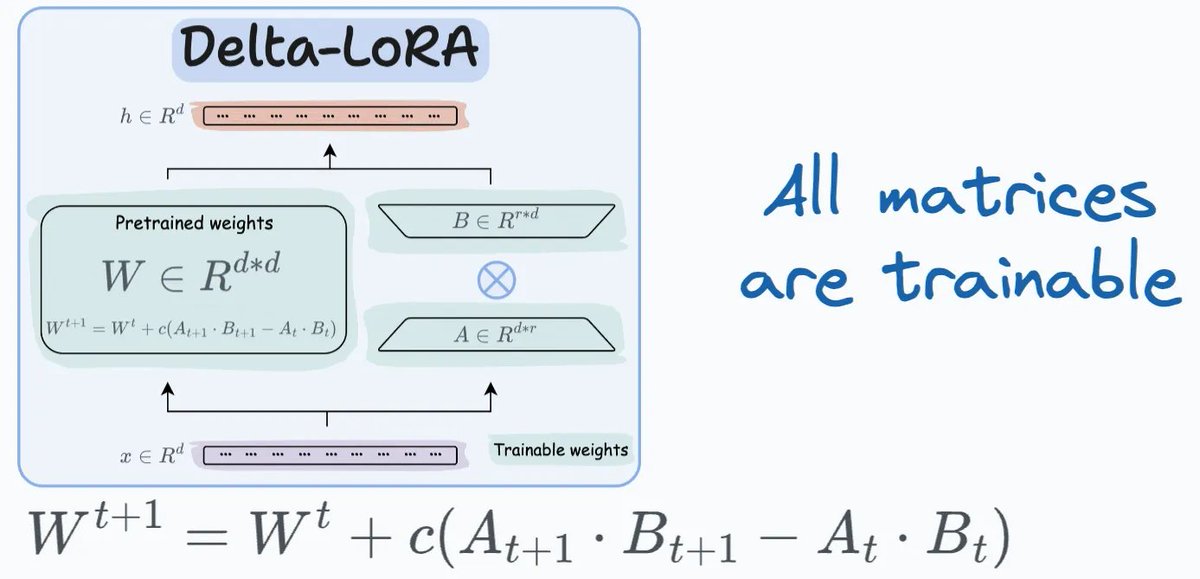 Hình minh họa thì đúng kiểu "cầm tay chỉ việc", dễ hiểu cực
Hình minh họa thì đúng kiểu "cầm tay chỉ việc", dễ hiểu cực
5. LoRA+ - Tăng tốc hội tụ
Cuối cùng là LoRA+, một kỹ thuật giúp tăng tốc độ hội tụ bằng cách áp dụng các tốc độ học (learning rates) khác nhau cho ma trận A và B. Cách này đã được chứng minh là mang lại kết quả tốt hơn trong việc tinh chỉnh, cho thấy tầm quan trọng của việc tối ưu hóa siêu tham số (hyperparameter) trong quá trình tinh chỉnh  Hình minh họa thì đúng kiểu "đỉnh của chóp", làm rõ sự khác biệt giữa các tốc độ học
Hình minh họa thì đúng kiểu "đỉnh của chóp", làm rõ sự khác biệt giữa các tốc độ học
Lịch sử phát triển và những điều cần lưu ý
Ngoài 5 kỹ thuật trên, thread còn điểm qua sự phát triển của các phương pháp tinh chỉnh LLMs qua thời gian, với một timeline siêu xịn bao gồm các phương pháp như QLoRA, AdaLoRA, và DORA 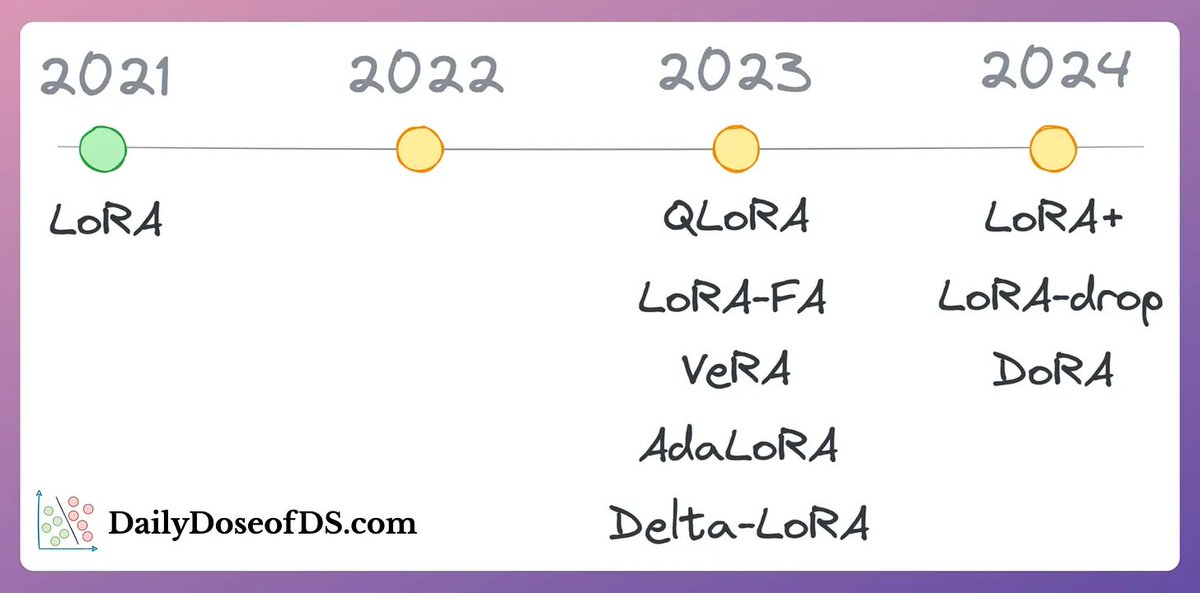 Bối cảnh lịch sử này cho thấy sự tiến bộ nhanh chóng trong lĩnh vực này và nỗ lực không ngừng để tìm ra các chiến lược tinh chỉnh hiệu quả hơn.
Bối cảnh lịch sử này cho thấy sự tiến bộ nhanh chóng trong lĩnh vực này và nỗ lực không ngừng để tìm ra các chiến lược tinh chỉnh hiệu quả hơn.
Nhìn lại, chất lượng của bộ dữ liệu tinh chỉnh đóng vai trò cực kỳ quan trọng trong việc quyết định thành công của các phương pháp này. Dữ liệu phải sạch, liên quan và đủ lớn để đạt hiệu suất tối ưu. Ngoài ra, việc tinh chỉnh siêu tham số như tốc độ học và kích thước batch cũng rất cần thiết để tối ưu hóa quá trình tinh chỉnh
Hơn nữa, việc tích hợp các kỹ thuật như học ít-shot (few-shot learning) và sinh dữ liệu có hỗ trợ truy xuất (RAG) có thể nâng cao thêm quá trình tinh chỉnh. Dù RAG không liên quan trực tiếp đến tinh chỉnh, nó cho phép truy xuất dữ liệu bên ngoài theo thời gian thực, cung cấp các phản hồi có ngữ cảnh, bổ sung cho khả năng của các LLMs đã được tinh chỉnh
Kết luận
Thread của anh bạn @_avichawla đúng là một bài "nhập môn" siêu chất về các kỹ thuật tinh chỉnh LLMs. Hiểu và áp dụng được mấy cách này, anh em có thể khai phá toàn bộ tiềm năng của các mô hình ngôn ngữ lớn, giúp chúng trở nên linh hoạt và hiệu quả hơn trong hàng loạt ứng dụng. Khi lĩnh vực này tiếp tục phát triển, việc cập nhật những tiến bộ mới sẽ là chìa khóa cho bất kỳ ai muốn tận dụng sức mạnh của LLMs trong công việc của mình.