Summary
View original tweet →Hiểu Về Chiến Lược "Chunking" Trong RAG: Hướng Dẫn Toàn Diện
Trong thế giới của Retrieval-Augmented Generation (RAG), cách chúng ta xử lý dữ liệu văn bản đóng vai trò cực kỳ quan trọng để tối ưu hiệu suất và đảm bảo tính liên quan về mặt ngữ nghĩa. Mới đây, một thread trên Twitter của anh bạn @_avichawla đã chia sẻ 5 chiến lược "chunking" siêu hiệu quả, giúp cải thiện chất lượng truy xuất thông tin từ các tài liệu lớn. Bài viết này sẽ mở rộng thêm về những chiến lược đó, giúp bạn hiểu sâu hơn về ý nghĩa và cách áp dụng chúng trong hệ thống RAG.
Thread mở đầu bằng một phần giới thiệu về "chunking", nhấn mạnh tầm quan trọng của nó khi xử lý các tài liệu lớn. Câu tweet đầu tiên đặt vấn đề rất rõ ràng: "5 chiến lược chunking cho RAG, giải thích siêu dễ hiểu (có cả hình minh họa):" Phần mở đầu này quan trọng lắm nha, vì nó làm nổi bật nhu cầu phải chunking hiệu quả trong các ứng dụng RAG, nơi mà kích thước của các "chunk" có thể ảnh hưởng trực tiếp đến độ chính xác của kết quả tìm kiếm.
Câu tweet thứ hai giải thích tại sao chunking lại cần thiết, đặc biệt khi xử lý các tài liệu siêu to khổng lồ. Nó nói rằng chunking là việc chia nhỏ tài liệu thành các phần dễ quản lý hơn để phù hợp với kích thước đầu vào của các mô hình embedding, từ đó cải thiện chất lượng truy xuất 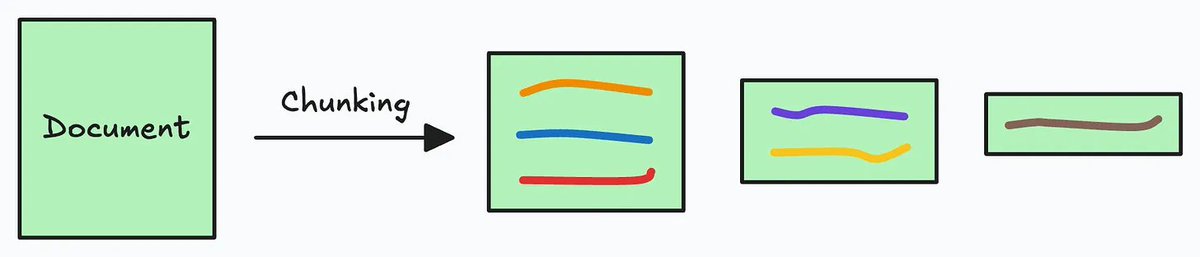 Nghe có vẻ hơi học thuật, nhưng ý chính là phải cân bằng giữa kích thước chunk và việc giữ được ý nghĩa ngữ cảnh.
Nghe có vẻ hơi học thuật, nhưng ý chính là phải cân bằng giữa kích thước chunk và việc giữ được ý nghĩa ngữ cảnh.
Tiếp theo, thread giới thiệu 5 chiến lược chunking, bắt đầu với Fixed-size chunking. Phương pháp này chia văn bản dựa trên số lượng ký tự, từ, hoặc token cố định, và thường có một chút chồng lấn giữa các chunk. Dễ làm, nhưng có thể làm đứt gãy cấu trúc câu, dẫn đến mất ngữ cảnh  Một ví dụ minh họa bằng hình ảnh cho thấy cách một câu có thể bị chia thành hai chunk chồng lấn nhau
Một ví dụ minh họa bằng hình ảnh cho thấy cách một câu có thể bị chia thành hai chunk chồng lấn nhau 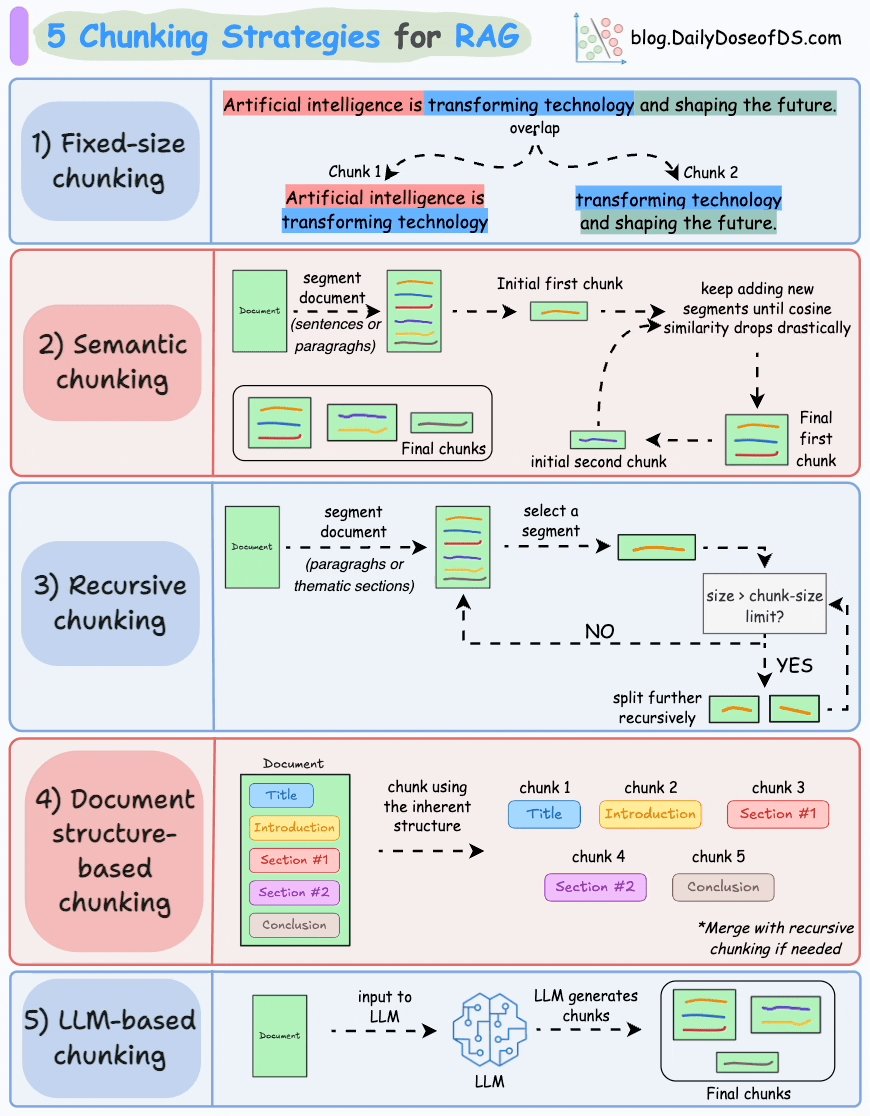
Chiến lược thứ hai, Semantic chunking, tập trung vào việc chia tài liệu dựa trên các đơn vị có ý nghĩa. Phương pháp này cải thiện chất lượng truy xuất bằng cách giữ nguyên ý nghĩa của văn bản, nhưng lại tốn kha khá tài nguyên tính toán 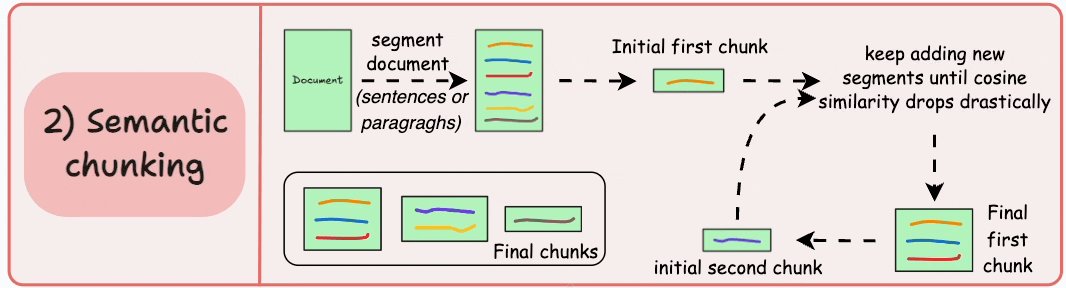 Thread có minh họa cách semantic chunking giữ được ngữ cảnh bằng cách sử dụng cosine similarity
Thread có minh họa cách semantic chunking giữ được ngữ cảnh bằng cách sử dụng cosine similarity
Recursive chunking là chiến lược thứ ba được nhắc đến. Cách này sử dụng các dấu phân cách tự nhiên như đoạn văn hoặc các phần trong tài liệu để tạo chunk. Nếu chunk nào vượt quá kích thước cho phép, nó sẽ được chia nhỏ thêm, đảm bảo dòng chảy tự nhiên của ngôn ngữ 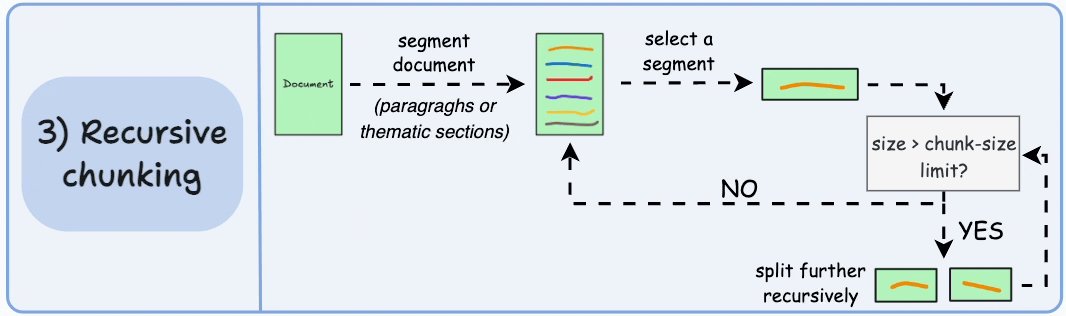 Một sơ đồ luồng minh họa quy trình này, làm nổi bật các điểm quyết định trong việc chunking
Một sơ đồ luồng minh họa quy trình này, làm nổi bật các điểm quyết định trong việc chunking
Chiến lược thứ tư, Document structure-based chunking, tận dụng cấu trúc sẵn có của tài liệu, như tiêu đề và các phần, để xác định chunk. Cách này hiệu quả với các tài liệu có cấu trúc rõ ràng, nhưng lại phụ thuộc vào việc tài liệu có được tổ chức tốt hay không 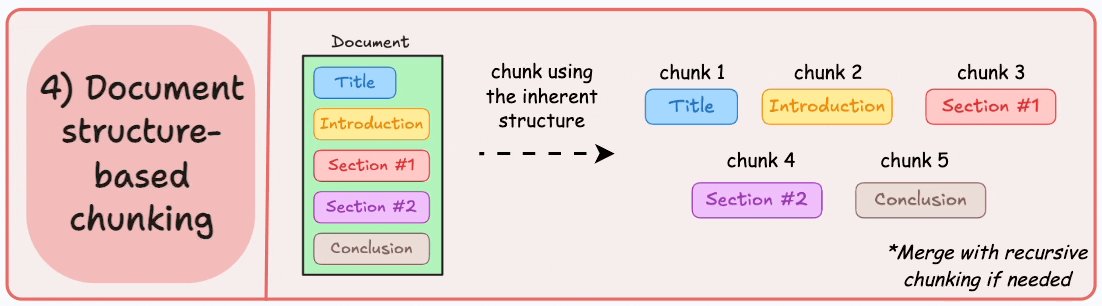 Một sơ đồ minh họa cách triển khai chiến lược này
Một sơ đồ minh họa cách triển khai chiến lược này
Cuối cùng, thread nói về LLM-based chunking, sử dụng mô hình ngôn ngữ (LLM) để tạo ra các chunk có ý nghĩa. Phương pháp này giữ được độ chính xác ngữ nghĩa nhưng lại tốn kém về mặt tính toán và bị giới hạn bởi độ dài ngữ cảnh của LLM  Một sơ đồ quy trình cung cấp cái nhìn sâu hơn về cách hoạt động của chiến lược này
Một sơ đồ quy trình cung cấp cái nhìn sâu hơn về cách hoạt động của chiến lược này
Những tweet cuối cùng nhấn mạnh rằng mỗi kỹ thuật đều có ưu và nhược điểm riêng. Việc chọn chiến lược chunking nào nên dựa vào tính chất của dữ liệu, khả năng của mô hình embedding, và tài nguyên tính toán sẵn có Câu tweet cuối cùng kết thúc bằng lời mời mọi người follow để cập nhật thêm các kiến thức về khoa học dữ liệu, machine learning, và RAG
Tóm lại, thread này cung cấp một nền tảng vững chắc để hiểu về các chiến lược chunking trong ứng dụng RAG. Tuy nhiên, cần cân nhắc thêm về những tác động rộng hơn của các chiến lược này. Ví dụ, việc chọn giữa fixed-size và semantic chunking có thể ảnh hưởng lớn đến chất lượng truy xuất. Fixed-size chunking thì rẻ hơn về mặt tính toán, nhưng có thể làm mất đi sự liền mạch của chủ đề. Trong khi đó, semantic chunking, dù phức tạp hơn, lại giữ được ngữ cảnh tốt hơn, khiến nó trở thành lựa chọn ưu tiên trong nhiều trường hợp.
Hơn nữa, ảnh hưởng của chunking đến hiệu suất RAG là không thể xem nhẹ. Việc thử nghiệm với các kích thước và phương pháp chunk khác nhau là rất cần thiết để tìm ra sự cân bằng tối ưu cho từng trường hợp cụ thể. Các công cụ như LangChain có thể hỗ trợ triển khai các chiến lược này một cách hiệu quả.
Cuối cùng, chọn đúng chiến lược chunking có thể giảm thiểu false positives và false negatives, cải thiện độ chính xác của hệ thống RAG. Khi lĩnh vực này tiếp tục phát triển, việc cập nhật thông tin về các chiến lược này sẽ rất quan trọng cho những ai muốn tận dụng RAG để nâng cao khả năng truy xuất và tạo dữ liệu.